Sse2 или streaming simd extensions 2
Что делать с проблемой?
Как уже понятно – ошибка “This program requires a computer that supports SSE2 instructions” возникает при попытке установить приложение, выполнение которого не будет поддержано процессором, ввиду его “древности”. Наиболее часто данная проблема встречается при установке актуальных версий браузеров (Firefox, Opera, Chrome, Internet Explorer), сторонних приложений (Office, Skype, антивирус Norton и т.д.), либо при переустановке ОС Windows.

Если вы получили данную ошибку, то выбора тут не много: обновлять железо – в крайнем случае материнскую плату и процессор, либо же устанавливать более раннюю версию софта. Если вы не желаете докупать новые детали на ПК, тогда отыщите для своей программы более старые версии, которые будут совместимы с требованиями процессора. Например, версии браузеров не требующие SSE2: Опера 20.0.1387.91, Хром 35.0.1870.2, Файерфокс ниже 48 версии. Вот полный список.

Нет поддержки, что делать?
Если поддержки того или иного формата нет – то придётся покупать специальный приставку. Они похожи на маленькие коробочки и поддерживают все современные цифровые стандарты. При это подключить цифровой ресивер можно к любому телевизору даже очень старому.

Рассказывать про каждый нет смысла, так как они примерно все одинаковые. У многих есть возможность подключаться к интернету через LAN порт или по Wi-Fi. Таким образом вы через приёмник сможете лазать по просторам интернета или смотреть тот же YouTube. На модели выше можно увидеть USB-порт для подключения жестких дисков, флэшек и других накопителей.
Что делать, если SSE2 не поддерживается?
Самый правильный вариант — обновлять компьютер (установить процессор с поддержкой SSE2, если это возможно) или приобрести новый.
Также можно попробовать поискать более ранние версии той программы, которая требует поддержку этого набора команд.
Является ли следующий код действительным для проверки того, поддерживает ли процессор набор инструкций SSE3?
Использование функции IsProcessorFeaturePresent() , по-видимому, не работает в Windows XP (см. http://msdn.microsoft.com/en-us/library/ms724482(v=vs.85).aspx).
Я создал GitHub-реестр, который обнаружит поддержку ЦП и ОС для всех основных расширений ISA x86: https://github.com/Mysticial/FeatureDetector
Здесь короче версия:
Сначала вам нужно получить доступ к инструкции CPUID:
Затем вы можете запустить следующий код:
Обратите внимание, что это только определяет, поддерживает ли процессор инструкции. Чтобы запустить их, вам также потребуется поддержка операционной системы
В частности, поддержка операционной системы требуется для:
- x64. (Вам нужна 64-разрядная ОС.)
- Инструкции, которые используют (AVX) 256-битные ymm регистры. См. ответ Энди Лутомирски о том, как это обнаружить.
- Инструкции, в которых используются 512-битные регистры zmm и маска (AVX512). Обнаружение поддержки ОС для AVX512 такое же, как у AVX, но с использованием флага 0xe6 вместо 0x6 .
Мистический ответ немного опасен – в нем объясняется, как определить поддержку ЦП, но не поддерживать ОС. Вам нужно использовать _xgetbv, чтобы проверить, активировала ли ОС требуемое расширенное состояние CPU. См. здесь для другого источника. Даже gcc совершил ту же ошибку. Мяч кода:
После недолгих поисков я также нашел решения от Intel:
Также обратите внимание, что в GCC есть некоторые специальные встроенные функции, которые вы можете использовать (см.: https://gcc.gnu.org/onlinedocs/gcc-4.9.2/gcc/X86-Built-in-Functions.html):
Если вы сложите это вместе с информацией выше, все будет хорошо.
На Mac OS это работает:
В моей машине это выводит это:
Как вы можете видеть из инструкций, написанных жирным шрифтом, SSE3 и куча других инструкций SIMD поддерживаются.
Чтобы добавить в Abhiroop ответ: В linux вы можете запустить эту команду оболочки, чтобы узнать функции, поддерживаемые вашим процессором.
cat/proc/cpuinfo | grep flags | uniq
На моей машине это печатает
Люди обычно оценивают процессор по количеству ядер, тактовой частоте, объему кэша и других показателях, редко обращая внимание на поддерживаемые им технологии. Отдельные из этих технологий нужны только для решения специфических заданий и в «домашнем» компьютере вряд ли когда-нибудь понадобятся
Наличие же других является непременным условием работы программ, необходимых для повседневного использования
Отдельные из этих технологий нужны только для решения специфических заданий и в «домашнем» компьютере вряд ли когда-нибудь понадобятся. Наличие же других является непременным условием работы программ, необходимых для повседневного использования.
Так, полюбившийся многим браузер Google Chrome не работает без поддержки процессором SSE2. Инструкции AVX могут в разы ускорить обработку фото- и видеоконтента. А недавно один мой знакомый на достаточно быстром Phenom II (6 ядер) не смог запустить игру Mafia 3, поскольку его процессор не поддерживает инструкции SSE4.2.
Если аббревиатуры SSE, MMX, AVX, SIMD вам ни о чем не говорят и вы хотели бы разобраться в этом вопросе, изложенная здесь информация станет неплохим подспорьем.
В кратких описаниях ниже упор сделан только на практическую ценность технологий. Пройдя по приведенным ссылкам, можно получить более подробные сведения о каждой из них.
Аббревиатура образована от MultiMedia eXtensions (мультимедийные расширения). Это набор инструкций процессора, предназначенных для ускорения обработки фото-, аудио- и видеоданных. Разработан компанией Intel, используется в процессорах с 1997 года и на момент внедрения обеспечивал до 70% прироста производительности. Сегодня вам вряд ли удастся встретить процессор без поддержки этой технологии. Подробнее.
3DNow!
Технология впервые была использована в 1998 году в процессорах AMD и стала развитием технологии MMX, значительно расширив возможности процессора в области обработи мультимедийных данных. Ее презентацию совместили с выходом игры Quake 2, в которой 3DNow! обеспечивала до 30% прироста быстродействия. Но широкого распространения 3DNow! не получила. Сейчас она заменена другими технологиями и в новых процессорах не используется. Подробнее.
Аббревиатура от от Streaming SIMD Extensions. SIMD расшифровывается как Single Instruction Multiple Data, что значит «одна инструкция – множество данных».
SSE впервые использована в 1999 году в процессорах Pentium ІІІ и стала своеобразным ответом компании Intel на разработанную компанией AMD технологию 3DNow!, устранив некоторые ее недостатки. SSE применяется процессором, когда нужно совершить одни и те же действия над разными данными и обеспечивает осуществление до 4 таких вычислений за 1 такт, чем обеспечивает существенный прирост быстродействия.
SSE используется огромным числом приложений. Процессоров без ее поддержки сегодня уже не встретишь. Подробнее.
Этот набор инструкций был разработан компанией Intel и впервые интегрирован в процессоры Pentium 4 (2000 – 2001 гг.).
Поддержка инструкций SSE2 является обязательным условием использования современного программного обеспечения. В частности, без этого набора команд не будут работать популярные браузеры Google Chrome и Яндекс-браузер. На компьютере без SSE2 также невозможно использовать Windows 8, Windows 10, Microsoft Office 2013 и др. Подробнее.
Набор из 13 инструкций, разработанный компанией Intel и впервые использованный ею в 2004 г. в процессорах с ядром Prescott. Позволяет процессору более эффективно использовать 128-битные регистры SSE.
Инструкции SSE3 заметно упростили ряд DSP- и 3D-операций. Практическая польза от них больше всего ощущается в приложениях, связанных с обработкой потоков графической информации, аудио- и видеосигналов. Подробнее.
Что означает ошибка «CPU does not have POPCNT» в игре Apex Legends
Для запуска софта необходимы определённые условия и даже если по всем параметрам компоненты устройства подходили, и ранее ничего не мешало старту, при обновлении были внесены изменения, в связи с чем, попутно и предъявлены новые требования к железу, а конкретнее к процессору.
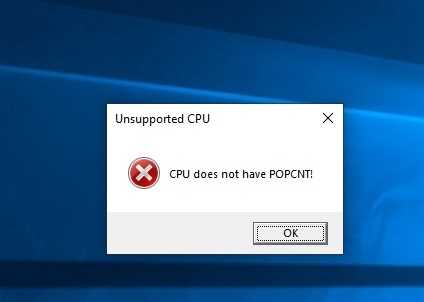
Ошибка игры Apex Legends: процессор не поддерживается
Для начала разберём, о чём именно сообщает ошибка. В первом случае, когда вместо запуска игры появляется окно с сообщением «CPU does not have SSSE 3», речь о том, что ваш процессор не поддерживает SSSE 3. Ошибка с текстом «CPU does not have POPCNT», появившаяся спустя неделю после релиза, сообщает об отсутствии поддержки процессором POPCNT, без которой игра попросту не запустится. Так, в уведомлении о каждой из ошибок сказано, что ЦП не обладает нужными параметрами для работы с Apex Legends.
Теперь нужно прояснить, что такое SSSE 3 и POPCNT в процессоре. Каждый, кто хорошо знаком с «внутренностями» системного блока знает, что характеристики CPU не ограничиваются количеством вычислительных ядер и тактовой частотой, среди параметров главного компонента аппаратного обеспечения компьютера есть и набор поддерживаемых инструкций. Эволюция в мире компьютерных технологий подразумевает и появление новых версий наборов инструкций, включаемых в современные процессоры. Новые команды называются SSSE 3 (Supplemental Streaming SIMD Extension 3). Компания Intel, внедрившая их в свои продукты, четвёртому расширению к названию добавила S вместо увеличения номера. В SSSE 3 имеется 16 уникальных команд, работающих с упакованными целыми, каждая из которых поддерживает 64-битные (ММХ) и 128-битные (ХММ) регистры. Что касается POPCNT, параметр входит в состав SSE 4.2, он же есть и в SSE4A от AMD. Есть три вариации инструкции – для 16-, 32 и 64-битных регистров.
Эти же инструкции, применяемые производителями процессоров, используют и разработчики софта, в том числе компьютерных игр, в случае с Apex Legends это SSSE 3 и POPCNT, которые в обязательном порядке должны поддерживаться вашим CPU. Если процессор не исполняет эти инструкции, равно не подходит по минимальным требованиям, значит и на запуск Apex Legends рассчитывать не стоит. Так, внесённые разработчиками Apex Legends коррективы, совершенствующие игру, отсеяли немалое количество устройств, способных её потянуть, чем и была обусловлена ошибка. При этом проблема вовсе не на стороне разработчика, всё дело в новых требованиях, которые отправили в лигу аутсайдеров все процессоры ранних поколений.
Чтобы проверить, соответствует ли ваш процессор требованиям, можно воспользоваться специализированной утилитой CPU-Z. Во вкладке «ЦП» в разделе «Набор инструкций» вы увидите все наборы, используемые ЦП. Для игры Apex Legends нужна обновлённая инструкция SSSE 3, а не устаревшая SSE 3, а также SSE 4.2, тогда как поддержка SSE 4.1 уже не подойдёт.
SSE2 dot product
64
bb·weights = ∑ bbi weightsi = bb1 weights1 + ... + bb64 weights64
i=1
The 64-bit times 64-byte dot product implements a kind of weighted population count similar than following loop approach, but completely unrolled and branchless:
int dotProduct(U64 bb, BYTE weights[])
{
U64 bit = 1;
int accu = 0;
for (int sq=0; sq < 64; sq++, bit += bit) {
if ( bb & bit) accu += weights;
// accu += weights & -(( bb & bit) == bit); // branchless 1
// accu += weights & -(( ~bb & bit) == 0); // branchless 2
}
return accu;
}
The SSE2 routine expands a bitboard as a vector of 64 bits into 64-bytes inside four 128-bit xmm registers, and performs the multiplication with the byte-vector by bitwise ‘and’, before it finally adds all bytes together. The bitboard is therefor manifolded eight times with a sequence of seven unpack and interleave instructions to remain the same expanded byte-order of the bits from the bitboards, before to mask and compare them with a vector of bytes with one appropriate bit set each.
#include <emmintrin.h>
#define XMM_ALIGN __declspec(align(16))
/* for average weights < 64 */
int dotProduct64(U64 bb, BYTE weights[] /* XMM_ALIGN */)
{
static const U64 XMM_ALIGN sbitmask = {
C64(0x8040201008040201),
C64(0x8040201008040201)
};
__m128i x0, x1, x2, x3, bm;
__m128i* pW = (__m128i*) weights;
bm = _mm_load_si128 ( (__m128i*) sbitmask);
x0 = _mm_cvtsi64x_si128(bb); // 0000000000000000:8040201008040201
// extend bits to bytes
x0 = _mm_unpacklo_epi8 (x0, x0); // 8080404020201010:0808040402020101
x2 = _mm_unpackhi_epi16 (x0, x0); // 8080808040404040:2020202010101010
x0 = _mm_unpacklo_epi16 (x0, x0); // 0808080804040404:0202020201010101
x1 = _mm_unpackhi_epi32 (x0, x0); // 0808080808080808:0404040404040404
x0 = _mm_unpacklo_epi32 (x0, x0); // 0202020202020202:0101010101010101
x3 = _mm_unpackhi_epi32 (x2, x2); // 8080808080808080:4040404040404040
x2 = _mm_unpacklo_epi32 (x2, x2); // 2020202020202020:1010101010101010
x0 = _mm_and_si128 (x0, bm);
x1 = _mm_and_si128 (x1, bm);
x2 = _mm_and_si128 (x2, bm);
x3 = _mm_and_si128 (x3, bm);
x0 = _mm_cmpeq_epi8 (x0, bm);
x1 = _mm_cmpeq_epi8 (x1, bm);
x2 = _mm_cmpeq_epi8 (x2, bm);
x3 = _mm_cmpeq_epi8 (x3, bm);
// multiply by "and" with -1 or 0
x0 = _mm_and_si128 (x0, pW);
x1 = _mm_and_si128 (x1, pW);
x2 = _mm_and_si128 (x2, pW);
x3 = _mm_and_si128 (x3, pW);
// add all bytes (with saturation)
x0 = _mm_adds_epu8 (x0, x1);
x0 = _mm_adds_epu8 (x0, x2);
x0 = _mm_adds_epu8 (x0, x3);
x0 = _mm_sad_epu8 (x0, _mm_setzero_si128 ());
return _mm_cvtsi128_si32(x0)
+ _mm_extract_epi16(x0, 4);
}
Adoptions
Here is a partial list of open source projects that have adopted for Arm/Aarch64 support.
- aether-game-utils is a collection of cross platform utilities for quickly creating small game prototypes in C++.
- Async is a set of c++ primitives that allows efficient and rapid development in C++17 on GNU/Linux systems.
- avec is a little library for using SIMD instructions on both x86 and Arm.
- bipartite_motif_finder as known as BMF (Bipartite Motif Finder) is an open source tool for finding co-occurences of sequence motifs in genomic sequences.
- Boo is a cross-platform windowing and event manager similar to SDL or SFML, with additional 3D rendering functionality.
- CARTA is a new visualization tool designed for viewing radio astronomy images in CASA, FITS, MIRIAD, and HDF5 formats (using the IDIA custom schema for HDF5).
- compute-runtime, the Intel Graphics Compute Runtime for oneAPI Level Zero and OpenCL Driver, provides compute API support (Level Zero, OpenCL) for Intel graphics hardware architectures (HD Graphics, Xe).
- dab-cmdline provides entries for the functionality to handle Digital audio broadcasting (DAB)/DAB+ through some simple calls.
- EDGE is an advanced OpenGL source port spawned from the DOOM engine, with focus on easy development and expansion for modders and end-users.
- Embree a collection of high-performance ray tracing kernels. Its target users are graphics application engineers who want to improve the performance of their photo-realistic rendering application by leveraging Embree’s performance-optimized ray tracing kernels.
- emp-tool aims to provide a benchmark for secure computation and allowing other researchers to experiment and extend.
- libscapi stands for the «Secure Computation API», providing reliable, efficient, and highly flexible cryptographic infrastructure.
- libmatoya is a cross-platform application development library, providing various features such as common cryptography tasks.
- Madronalib enables efficient audio DSP on SIMD processors with readable and brief C++ code.
- minimap2 is a versatile sequence alignment program that aligns DNA or mRNA sequences against a large reference database.
- MMseqs2 (Many-against-Many sequence searching) is a software suite to search and cluster huge protein and nucleotide sequence sets.
- MRIcroGL is a cross-platform tool for viewing NIfTI, DICOM, MGH, MHD, NRRD, AFNI format medical images.
- N2 is an approximate nearest neighborhoods algorithm library written in C++, providing a much faster search speed than other implementations when modeling large dataset.
- niimath is a general image calculator with superior performance.
- OBS Studio is software designed for capturing, compositing, encoding, recording, and streaming video content, efficiently.
- OGRE is a scene-oriented, flexible 3D engine written in C++ designed to make it easier and more intuitive for developers to produce games and demos utilising 3D hardware.
- OpenXRay is an improved version of the X-Ray engine, used in world famous S.T.A.L.K.E.R. game series by GSC Game World.
- PFFFT does 1D Fast Fourier Transforms, of single precision real and complex vectors.
- simd_utils is a header-only library implementing common mathematical functions using SIMD intrinsics.
- SMhasher provides comprehensive Hash function quality and speed tests.
- Spack is a multi-platform package manager that builds and installs multiple versions and configurations of software.
- srsLTE is an open source SDR LTE software suite.
- Surge is an open source digital synthesizer.
SSE2 Miscellaneous Instructions
The SSE2 instructions described below provide
additional functionality for caching non-temporal data when storing data from XMM
registers to memory, and provide additional control of instruction ordering on store
operations.
|
Solaris Mnemonic |
Intel/AMD Mnemonic |
Description |
Notes |
|---|---|---|---|
|
clflush |
CLFLUSH |
flushes and invalidates a memory operand and its associated cache line from |
|
|
lfence |
LFENCE |
serializes load operations |
|
|
maskmovdqu |
MASKMOVDQU |
non-temporal store of selected bytes from an XMM register into memory |
|
|
mfence |
MFENCE |
serializes load and store operations |
|
|
movntdq |
MOVNTDQ |
non-temporal store of double quadword from an XMM register into memory |
|
|
movnti |
MOVNTI |
non-temporal store of a doubleword from a general-purpose register into memory |
movntiq valid only under -xarch=amd64 |
|
movntpd |
MOVNTPD |
non-temporal store of two packed double-precision floating-point values from |
|
|
pause |
PAUSE |
improves the performance of spin-wait loops |
AVX-512: а не многовато-ли?
AVX2 ещё только начал появляться на рынке процессоров, а Intel уже плела маниакальные планы относительно его преемника, AVX-512, и общий настрой среди разработчиков был такой: «больше регистров богу регистров!». Мало того, что этих самых регистров снова вдвое больше, и они снова вдвое увеличились в размере, так ещё и появился стек новых инструкций и поддержка устаревших.
Первой партией чипов, на которых поднялся в воздух набор функций AVX-512, стала серия Xeon Phi 7200 – второе поколение громоздких и очень многоядерных процессоров Intel, ориентированных на рынок суперкомпьютеров.

72-ядерный 288-потоковый Knights Landing Xeon Phi.
В отличие от всех предыдущих реализаций, новый набор векторных инструкций состоял из 19-и компонентов: базового – AVX-512F, – необходимого для обеспечения совместимости, и множества весьма специфических. Эти дополнительные наборы охватывают такие области операций, как обратная математика, целочисленные FMA и алгоритмы свёрточной (конволюционной) нейронной сети (CNN-алгоритмы).
Первоначально AVX-512 был только прерогативой крупнейших чипов Intel, предназначенных для рабочих станций и серверов, но теперь их недавние архитектуры Ice Lake и Tiger Lake также поддерживают его. Да, не удивляйтесь: вы можете купить легкий ноутбук с процессором, имеющим 512-битные векторные блоки.
Это может показаться круто. А может и не показаться – в зависимости от вашей точки зрения. Регистры на кристалле CPU обычно группируются в так называемом регистровом файле, как видно на макрофото ниже.
 2-ядерный Intel Skylake
2-ядерный Intel Skylake
Желтым прямоугольником выделен файл векторных регистров, красный прямоугольник – это наиболее вероятное расположение файла целочисленного регистра
Обратите внимание, насколько файл векторного регистра больше integer-регистра. В Skylake используются 256-битные регистры AVX2, следовательно аналогичный векторный регистровый файл AVX-512 занял бы на таком же кристалле в четыре раза больше места: вдвое больше, потому что вдвое больше их размер, и ещё вдвое – потому что самих регистров вдвое больше.
А очень-ли нужно такое количество векторных регистров маленькому чипу, который должен быть максимально мобильным? Хоть речь и не о лишних килограммах в ноутбуке, а лишь о небольшой части площади ядра процессора, каждый квадратный миллиметр имеет значение, когда речь идет о миниатюризации мобильных устройств и наиболее эффективном использовании доступного пространства в них.
И учитывая, что использование AVX в любом виде приводит к автоматическому уменьшению тактовой частоты, использование AVX-512 на таких платформах скорее всего приведет к ещё более сомнительным издержкам по сравнению с любым из своих предшественников, поскольку при работе он потребляет еще больше энергии.

И проблема AVX-512 не только в применении к небольшим мобильным процессорам. Разработчикам, пишущим код для работы на рабочих станциях и серверах, и для которых увеличение возможностей векторных расширений действительно важный вопрос, потребуется создавать несколько версий кода. Это связано с тем, что не все процессоры с AVX-512 работают с одинаковым набором команд.
Например, набор IFMA (Integer Fused Multiply Add, «целочисленное умножение-сложение с однократным округлением») доступен только на процессорах Cannon, Ice и Tiger Lake. В то время как процессоры на архитектуре Cooper и Cascade Lake его не поддерживают, несмотря на то, что они относятся к сегменту процессоров для серверов и рабочих станций.
Стоит отметить, что AMD не предлагает поддержку AVX-512, и не собирается. По их мнению, обработка массивных векторных вычислений – это прерогатива GPU. С AMD полностью солидарна Nvidia, и обе компании уже выпустили продукты специально для таких нужд.
Различия между MMX и SSE2
SSE2 расширяет инструкции MMX для работы с регистрами XMM. Следовательно, можно преобразовать весь существующий код MMX в эквивалент SSE2. Поскольку регистр SSE2 в два раза длиннее регистра MMX, может потребоваться изменить счетчики циклов и доступ к памяти, чтобы учесть это. Однако доступны 8-байтовые загрузки и сохранения в XMM, поэтому это не обязательно.
Хотя одна инструкция SSE2 может обрабатывать вдвое больше данных, чем инструкция MMX, производительность может незначительно повыситься. Две основные причины: доступ к данным SSE2 в памяти, не выровненной по 16-байтовой границе, может привести к значительным потерям, а пропускная способность инструкций SSE2 в более старых реализациях x86 была вдвое меньше, чем для инструкций MMX. Intel решила первую проблему, добавив инструкцию в SSE3, чтобы уменьшить накладные расходы на доступ к невыровненным данным и улучшить общую производительность несовпадающих нагрузок, и последнюю проблему, расширив механизм выполнения в своей микроархитектуре Core в Core 2 Duo и более поздних продуктах.
Поскольку файлы регистров MMX и x87 являются псевдонимами друг друга, использование MMX не позволит инструкциям x87 работать должным образом. После использования MMX программист должен использовать инструкцию emms (C: _mm_empty ()) для восстановления работы в регистровом файле x87. В некоторых операционных системах x87 используется не очень часто, но все же может использоваться в некоторых критических областях, таких как pow (), где требуется дополнительная точность. В таких случаях поврежденное состояние с плавающей запятой, вызванное отказом в выдаче emms, может остаться незамеченным для миллионов инструкций, прежде чем в конечном итоге приведет к сбою процедуры с плавающей запятой, возвращающей NaN. Поскольку проблема не проявляется локально в коде MMX, поиск и исправление ошибки может занять очень много времени. Поскольку SSE2 не имеет этой проблемы, обычно обеспечивает гораздо лучшую пропускную способность и предоставляет больше регистров в 64-битном коде, его следует предпочесть почти для всех работ по векторизации.
