Как найти повторяющиеся значения в таблице excel
Поиск повторяющихся значений включая первые вхождения.
Предположим, что у вас в колонке А находится набор каких-то показателей, среди которых, вероятно, есть одинаковые. Это могут быть номера заказов, названия товаров, имена клиентов и прочие данные. Если ваша задача — найти их, то следующая формула для вас:
Где А2 — первая ячейка из области для поиска.
Просто введите это выражение в любую ячейку и протяните вниз вдоль всей колонки, которую нужно проверить на дубликаты.

Как вы могли заметить на скриншоте выше, формула возвращает ИСТИНА, если имеются совпадения. А для встречающихся только 1 раз значений она показывает ЛОЖЬ.
Подсказка! Если вы ищите повторы в определенной области, а не во всей колонке, обозначьте нужный диапазон и “зафиксируйте” его знаками $. Это значительно ускорит вычисления. Например, если вы ищете в A2:A8, используйте
Если вас путает ИСТИНА и ЛОЖЬ в статусной колонке и вы не хотите держать в уме, что из них означает повторяющееся, а что — уникальное, заверните свою СЧЕТЕСЛИ в функцию ЕСЛИ и укажите любое слово, которое должно соответствовать дубликатам и уникальным:
Если же вам нужно, чтобы формула указывала только на дубли, замените «Уникальное» на пустоту («»):


В этом случае Эксель отметит только неуникальные записи, оставляя пустую ячейку напротив уникальных.
Поиск неуникальных значений без учета первых вхождений
Вы наверняка обратили внимание, что в примерах выше дубликатами обозначаются абсолютно все найденные совпадения. Но зачастую задача заключается в поиске только повторов, оставляя первые вхождения нетронутыми
То есть, когда что-то встречается в первый раз, оно однозначно еще не может быть дубликатом.
Если вам нужно указать только совпадения, давайте немного изменим:
На скриншоте ниже вы видите эту формулу в деле.

Нетрудно заметить, что она не обозначает первое появление слова, а начинает отсчет со второго.
Чувствительный к регистру поиск дубликатов
Хочу обратить ваше внимание на то, что хоть формулы выше и находят 100%-дубликаты, есть один тонкий момент — они не чувствительны к регистру. Быть может, для вас это не принципиально
Но если в ваших данных абв, Абв и АБВ — это три разных параметра – то этот пример для вас.
Как вы могли уже догадаться, выражения, использованные нами ранее, с такой задачей не справятся. Здесь нужно выполнить более тонкий поиск, с чем нам поможет следующая функция массива:
Не забывайте, что формулы массива вводятся комбиинацией Ctrl + Shift + Enter.
Если вернуться к содержанию, то здесь используется функция СОВПАД для сравнения целевой ячейки со всеми остальными ячейками с выбранной области. Результат возвращается в виде ИСТИНА (совпадение) или ЛОЖЬ (не совпадение), которые затем преобразуются в массив из 1 и 0 при помощи оператора (—).
После этого, функция СУММ складывает эти числа. И если полученный результат больше 1, функция ЕСЛИ сообщает о найденном дубликате.
Если вы взглянете на следующий скриншот, вы убедитесь, что поиск действительно учитывает регистр при обнаружении дубликатов:

Смородина и арбуз, которые встречаются дважды, не отмечены в нашем поиске, так как регистр первых букв у них отличается.
Метод 5: формула для удаления повторяющихся строк
Данный метод является самым сложным из всех перечисленных, так как предназначается исключительно для тех пользователей, кто разбирается в функциях и особенностях этой программы. Ведь метод предполагает использование сложной формулы. Выглядит она следующим образом: =ЕСЛИОШИБКА(ИНДЕКС(адрес_столбца;ПОИСКПОЗ(0;СЧЁТЕСЛИ(адрес_шапки_столбца_дубликатов:адрес_шапки_столбца_дубликатов(абсолютный);адрес_столбца;)+ЕСЛИ(СЧЁТЕСЛИ(адрес_столбца;адрес_столбца;)>1;0;1);0));””). Теперь необходимо определиться, как именно ей пользоваться и где применять:
- Первым делом следует добавить новый столбец, который будет предназначен исключительно для дубликатов.
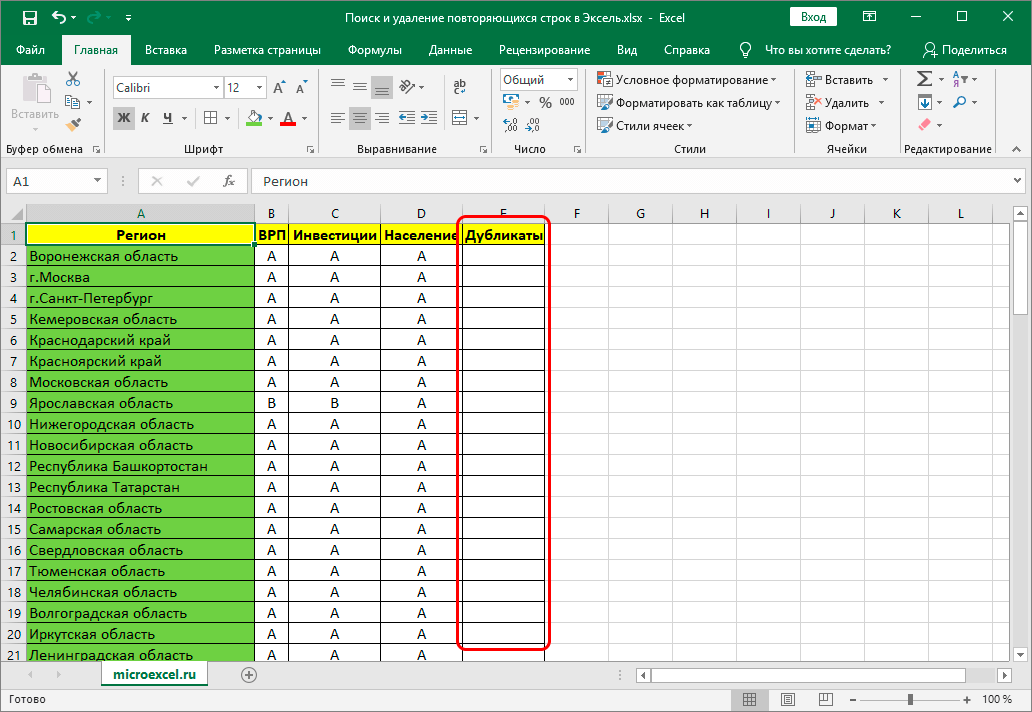 Создаем дополнительный столбец в таблице
Создаем дополнительный столбец в таблице
- Выделите верхнюю ячейку и введите в нее формулу: =ЕСЛИОШИБКА(ИНДЕКС(A2:A90;ПОИСКПОЗ(0;СЧЁТЕСЛИ(E1:$E$1;A2:A90)+ЕСЛИ(СЧЁТЕСЛИ(A2:A90;А2:А90)>1;0;1);0));””).
- Теперь выделите полностью столбец для дубликатов, не трогая шапку.
- Поставьте курсор в конец формулы, только будьте внимательны с этим пунктом, так как далеко не всегда формулу хорошо видно в ячейке, лучше воспользоваться верхней строкой поиска и внимательно посмотреть правильное расположение курсора.
- После установки курсора необходимо нажать на кнопку F2 на клавиатуре.
- После этого нужно нажать сочетание клавиш «Ctrl+Shift+Enter».
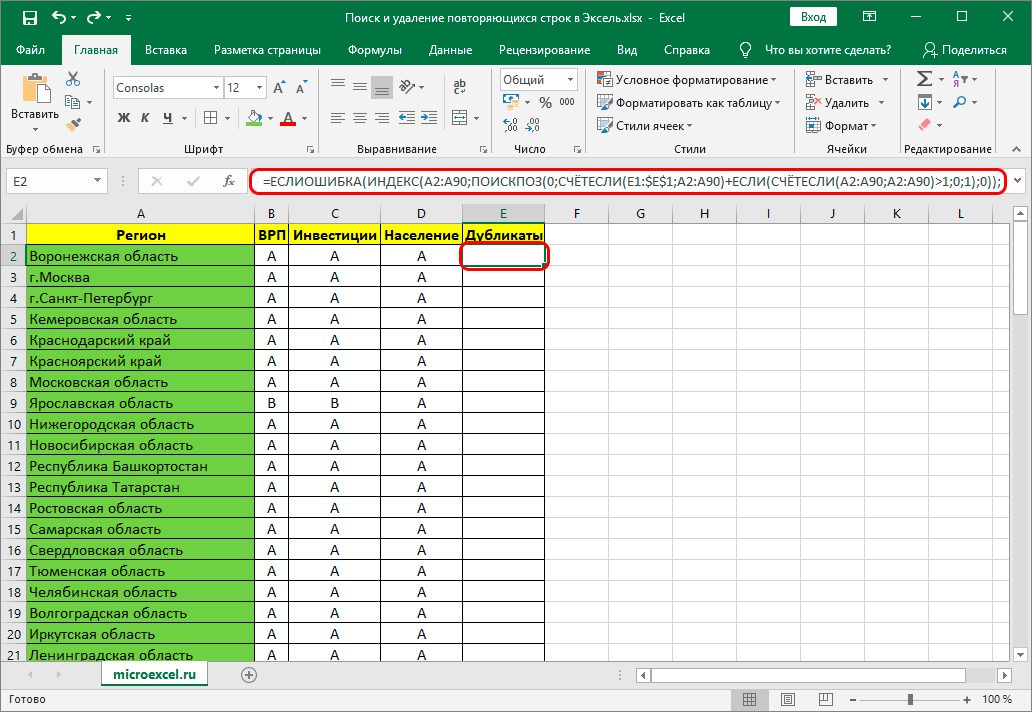 Вставляем и редактируем формулу
Вставляем и редактируем формулу
- Благодаря выполненным действиям можно будет корректно заполнить формулу необходимыми сведениями из таблицы.
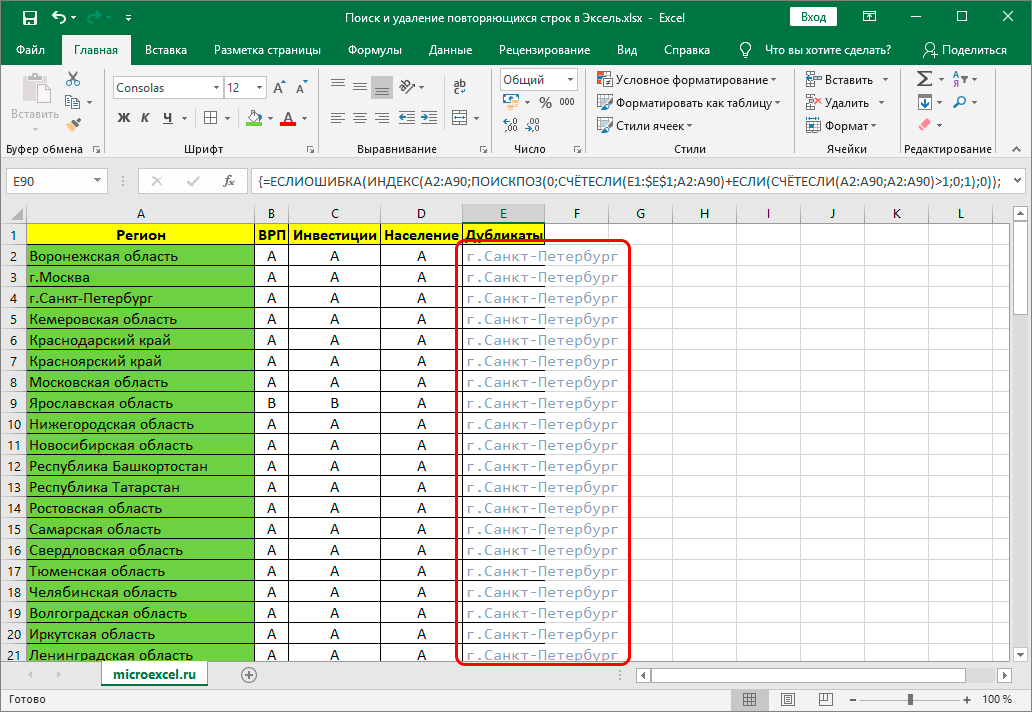 Проверяем полученный результат
Проверяем полученный результат
Подсчет количества каждого из дубликатов.
Если у вас, к примеру, есть столбец с наименованиями товаров, вам часто может понадобиться узнать, сколько дубликатов имеется для каждого из них.
Чтобы узнать, сколько раз та или иная запись встречается в вашей рабочей таблице Excel, используйте простую формулу COUNTIF, где A2 — первый, а A8 — последний элемент списка:
Как показано на следующем снимке экрана, программа подсчитывает вхождения каждого элемента: «Fanta» встречается 2 раза, «Sprite» — 3 раза, и так далее.

Если вы хотите указать на 1- е , 2- е , 3- е и т. д. появление каждого элемента, используйте:
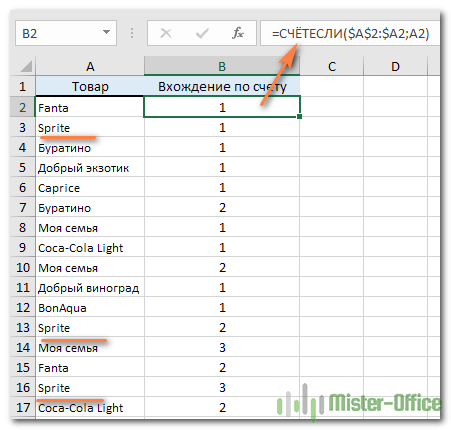
Мы отметили на рисунке первое, второе и третье появление Sprite.
Аналогичным образом вы можете посчитать количество повторяющихся строк. Единственное отличие состоит в том, что вам нужно будет использовать функцию СЧЁТЕСЛИМН() вместо СЧЁТЕСЛИ(). Например:

На скриншоте мы отметили одинаковые строки.
После подсчета повторяющихся значений вы можете скрыть уникальные и просматривать только одинаковые, или наоборот. Для этого примените автофильтр Excel.
Как извлечь дубликаты из диапазона.
Формулы, которые мы описывали выше, позволяют находить дубликаты в определенном столбце. Но часто речь идет о нескольких столбцах, то есть о диапазоне данных.
Рассмотрим это на примере числовой матрицы. К сожалению, с символьными значениями этот метод не работает.

При помощи формулы массива
вы можете получить упорядоченный по возрастанию список дубликатов. Для этого введите это выражение в нужную ячейку и нажмите .
Затем протащите маркер заполнения вниз на сколько это необходимо.
Чтобы убрать сообщения об ошибке, когда дублирующиеся значения закончатся, можно использовать функцию ЕСЛИОШИБКА:
Также обратите внимание, что приведенное выше выражение рассчитано на то, что оно будет записано во второй строке. Соответственно выше него будет одна пустая строка
Поэтому если вам нужно разместить его, к примеру, в ячейке K4, то выражение СТРОКА()-1 в конце замените на СТРОКА()-3.
Обработка найденных дубликатов
Отлично, мы нашли записи в первом столбце, которые также присутствуют во втором столбце. Теперь нам нужно что-то с ними делать. Просматривать все повторяющиеся записи в таблице вручную довольно неэффективно и занимает слишком много времени. Существуют пути получше.
Показать только повторяющиеся строки в столбце А
Если Ваши столбцы не имеют заголовков, то их необходимо добавить. Для этого поместите курсор на число, обозначающее первую строку, при этом он превратится в чёрную стрелку, как показано на рисунке ниже:
Кликните правой кнопкой мыши и в контекстном меню выберите Insert (Вставить):
Дайте названия столбцам, например, “Name” и “Duplicate?” Затем откройте вкладку Data (Данные) и нажмите Filter (Фильтр):
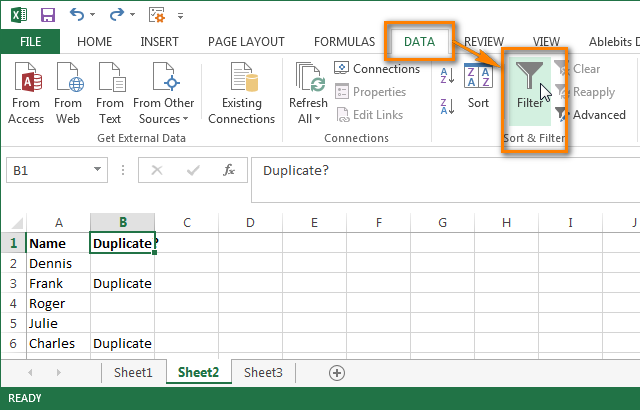
После этого нажмите меленькую серую стрелку рядом с “Duplicate?“, чтобы раскрыть меню фильтра; снимите галочки со всех элементов этого списка, кроме Duplicate, и нажмите ОК.
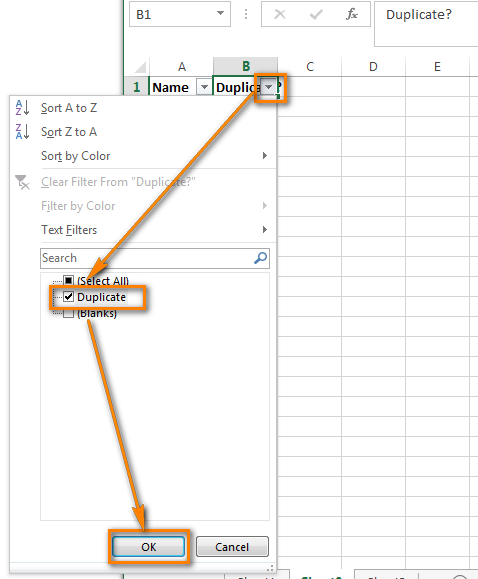
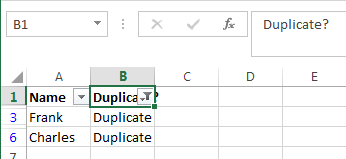
Вот и всё, теперь Вы видите только те элементы столбца А, которые дублируются в столбце В. В нашей учебной таблице таких ячеек всего две, но, как Вы понимаете, на практике их встретится намного больше.
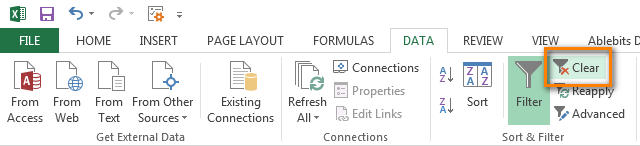
Чтобы снова отобразить все строки столбца А, кликните символ фильтра в столбце В, который теперь выглядит как воронка с маленькой стрелочкой и выберите Select all (Выделить все). Либо Вы можете сделать то же самое через Ленту, нажав Data (Данные) > Select & Filter (Сортировка и фильтр) > Clear (Очистить), как показано на снимке экрана ниже:
Изменение цвета или выделение найденных дубликатов
Если пометки “Duplicate” не достаточно для Ваших целей, и Вы хотите отметить повторяющиеся ячейки другим цветом шрифта, заливки или каким-либо другим способом…
В этом случае отфильтруйте дубликаты, как показано выше, выделите все отфильтрованные ячейки и нажмите Ctrl+1, чтобы открыть диалоговое окно Format Cells (Формат ячеек). В качестве примера, давайте изменим цвет заливки ячеек в строках с дубликатами на ярко-жёлтый. Конечно, Вы можете изменить цвет заливки при помощи инструмента Fill (Цвет заливки) на вкладке Home (Главная), но преимущество диалогового окна Format Cells (Формат ячеек) в том, что можно настроить одновременно все параметры форматирования.
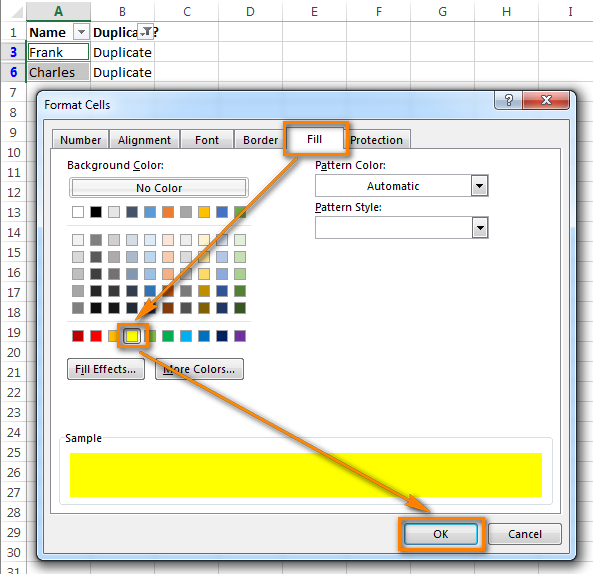
Теперь Вы точно не пропустите ни одной ячейки с дубликатами:
Удаление повторяющихся значений из первого столбца
Отфильтруйте таблицу так, чтобы показаны были только ячейки с повторяющимися значениями, и выделите эти ячейки.
Если 2 столбца, которые Вы сравниваете, находятся на разных листах, то есть в разных таблицах, кликните правой кнопкой мыши выделенный диапазон и в контекстном меню выберите Delete Row (Удалить строку):
Нажмите ОК, когда Excel попросит Вас подтвердить, что Вы действительно хотите удалить всю строку листа и после этого очистите фильтр. Как видите, остались только строки с уникальными значениями:
Если 2 столбца расположены на одном листе, вплотную друг другу (смежные) или не вплотную друг к другу (не смежные), то процесс удаления дубликатов будет чуть сложнее. Мы не можем удалить всю строку с повторяющимися значениями, поскольку так мы удалим ячейки и из второго столбца тоже. Итак, чтобы оставить только уникальные записи в столбце А, сделайте следующее:
- Отфильтруйте таблицу так, чтобы отображались только дублирующиеся значения, и выделите эти ячейки. Кликните по ним правой кнопкой мыши и в контекстном меню выберите Clear contents (Очистить содержимое).
- Очистите фильтр.
- Выделите все ячейки в столбце А, начиная с ячейки А1 вплоть до самой нижней, содержащей данные.
- Откройте вкладку Data (Данные) и нажмите Sort A to Z (Сортировка от А до Я). В открывшемся диалоговом окне выберите пункт Continue with the current selection (Сортировать в пределах указанного выделения) и нажмите кнопку Sort (Сортировка):
- Удалите столбец с формулой, он Вам больше не понадобится, с этого момента у Вас остались только уникальные значения.
- Вот и всё, теперь столбец А содержит только уникальные данные, которых нет в столбце В:
Как видите, удалить дубликаты из двух столбцов в Excel при помощи формул – это не так уж сложно.
Метод 5: формула для удаления повторяющихся строк
Последний метод достаточно сложен, и им мало, кто пользуется, так как здесь предполагается использование сложной формулы, объединяющей в себе несколько простых функций. И чтобы настроить формулу для собственной таблицы с данными, нужен определенный опыт и навыки работы в Эксель.
Формула, позволяющая искать пересечения в пределах конкретного столбца в общем виде выглядит так:
Давайте посмотрим, как с ней работать на примере нашей таблицы:
- Добавляем в конце таблицы новый столбец, специально предназначенный для отображения повторяющихся значений (дубликаты).
- В верхнюю ячейку нового столбца (не считая шапки) вводим формулу, которая для данного конкретного примера будет иметь вид ниже, и жмем Enter: =ЕСЛИОШИБКА(ИНДЕКС(A2:A90;ПОИСКПОЗ(0;СЧЁТЕСЛИ(E1:$E$1;A2:A90)+ЕСЛИ(СЧЁТЕСЛИ(A2:A90;A2:A90)>1;0;1);0));»») .
- Выделяем до конца новый столбец для задвоенных данных, шапку при этом не трогаем. Далее действуем строго по инструкции:
- ставим курсор в конец строки формул (нужно убедиться, что это, действительно, конец строки, так как в некоторых случаях длинная формула не помещается в пределах одной строки);
- жмем служебную клавишу F2 на клавиатуре;
- затем нажимаем сочетание клавиш Ctrl+SHIFT+Enter.
- Эти действия позволяют корректно заполнить формулой, содержащей ссылки на массивы, все ячейки столбца. Проверяем результат.
Как уже было сказано выше, этот метод сложен и функционально ограничен, так как не предполагает удаления найденных столбцов. Поэтому, при прочих равных условиях, рекомендуется использовать один из ранее описанных методов, более логически понятных и, зачастую, более эффективных.
Как быстро найти дубликаты в списке?
В одной из предыдущих статей мы рассмотрели вопрос: ” Как быстро удалить дубликаты в списке? “. В этом материале я расскажу о трех способах поиска дубликатов в списке.
Первый способ (сортировка):
Выделяем наш список, в котором необходимо найти повторяющиеся значения, переходим во вкладку меню “Данные”, в разделе “Сортировка и фильтр” нажимаем кнопку ” Сортировка по убыванию ” или “Сортировка по возрастанию”:
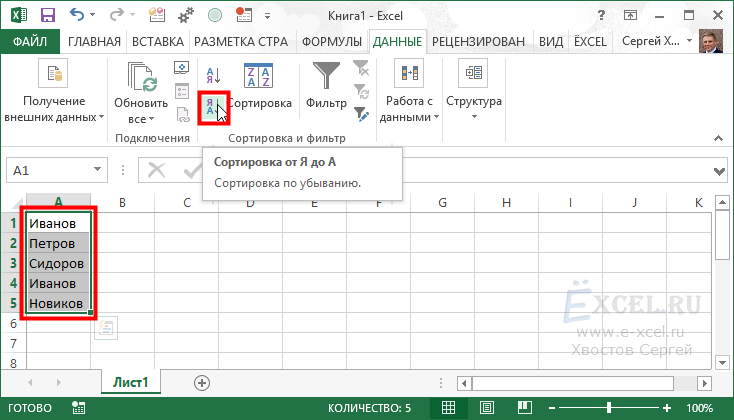
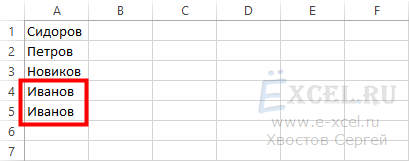
Наш список будет отсортирован и в нем визуально будет проще найти повторяющиеся значения:
Второй способ (условное форматирование):
Выделяем наш список, в котором необходимо найти повторяющиеся значения, переходим во вкладку меню “Главная”, в разделе “Стили” нажимаем “Условное форматирование” в выпавшем списке выбираем пункт “Правила выделения ячеек”, в списке вариантов выбираем “Повторяющиеся значения. “:
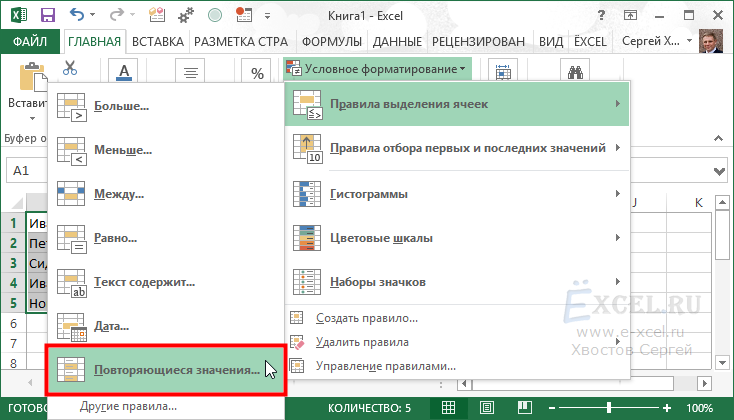
В открывшемся диалоговом окне нажимаем “ОК”:
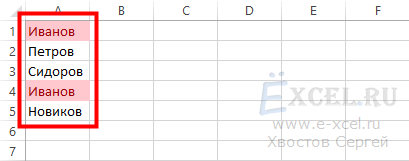
Все повторяющиеся значения в списке будут выделены цветом:
Третий способ (сводная таблица):
Выделяем наш список, в котором необходимо найти повторяющиеся значения, переходим во вкладку меню “Вставка”, в разделе “Таблицы” нажимаем кнопку “Сводная таблица”:
В открывшемся диалоговом окне нажимаем “ОК”:
Перетаскиваем поле со списком (в моем случае это “Фамилия”) в “СТРОКИ” и в “ЗНАЧЕНИЯ”:
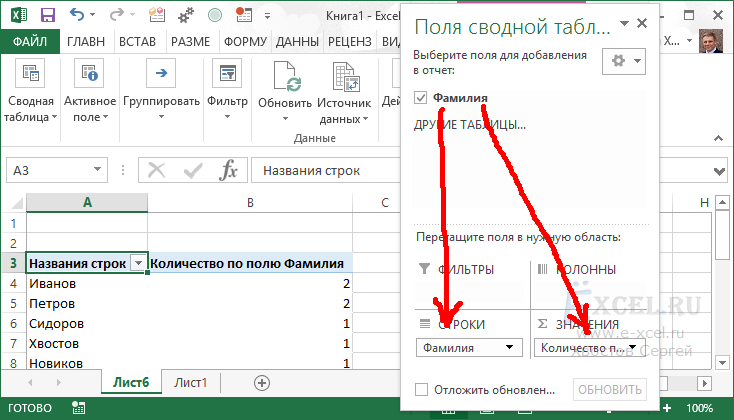
Встаем в первую ячейку с данными сводной таблицы, переходи во вкладку меню “Данные”, в разделе “Сортировка и фильтр” нажимаем кнопку “Сортировка по убыванию”:
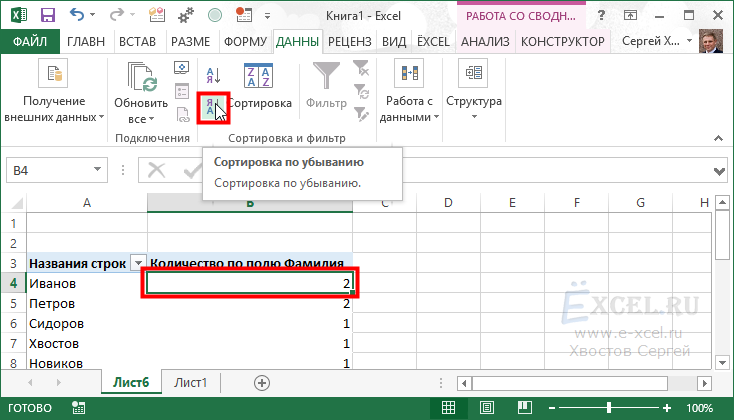
В верхней части сводной таблицы получаем все повторяющиеся данные с количеством повторов:
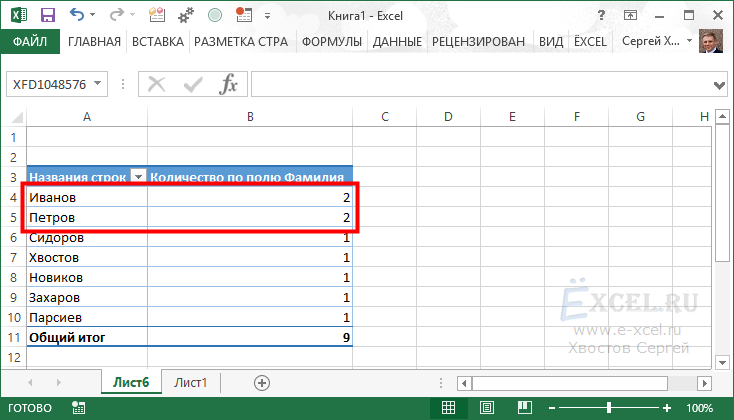
Первый и второй варианты безусловно быстрее, но они больше подходят для небольших списков
Если список очень большой и вам важно узнать сколько раз повторяются те или иные данные лучше воспользоваться третьим способом
Поиск дубликатов при помощи встроенных фильтров Excel
Организовав данные в виде списка, Вы можете применять к ним различные фильтры. В зависимости от набора данных, который у Вас есть, Вы можете отфильтровать список по одному или нескольким столбцам. Поскольку я использую Office 2010, то мне достаточно выделить верхнюю строку, в которой находятся заголовки, затем перейти на вкладку Data (Данные) и нажать команду Filter (Фильтр). Возле каждого из заголовков появятся направленные вниз треугольные стрелки (иконки выпадающих меню), как на рисунке ниже.
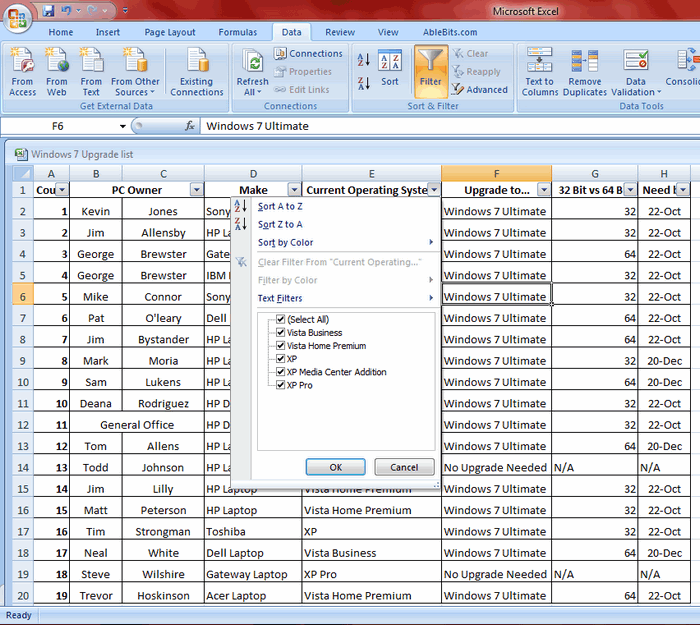
Если нажать одну из этих стрелок, откроется выпадающее меню фильтра, которое содержит всю информацию по данному столбцу. Выберите любой элемент из этого списка, и Excel отобразит данные в соответствии с Вашим выбором. Это быстрый способ подвести итог или увидеть объём выбранных данных. Вы можете убрать галочку с пункта Select All (Выделить все), а затем выбрать один или несколько нужных элементов. Excel покажет только те строки, которые содержат выбранные Вами пункты. Так гораздо проще найти дубликаты, если они есть.
После настройки фильтра Вы можете удалить дубликаты строк, подвести промежуточные итоги или дополнительно отфильтровать данные по другому столбцу. Вы можете редактировать данные в таблице так, как Вам нужно. На примере ниже у меня выбраны элементы XP и XP Pro.
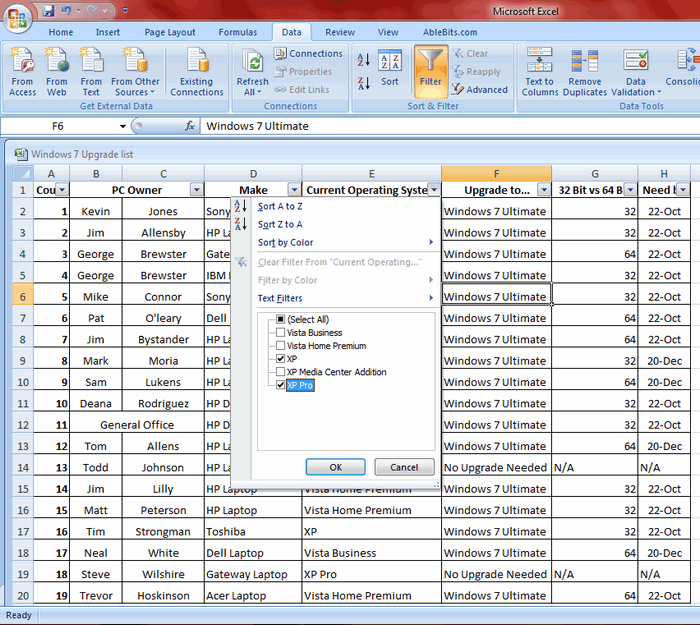
В результате работы фильтра, Excel отображает только те строки, в которых содержатся выбранные мной элементы (т.е. людей на чьём компьютере установлены XP и XP Pro). Можно выбрать любую другую комбинацию данных, а если нужно, то даже настроить фильтры сразу в нескольких столбцах.
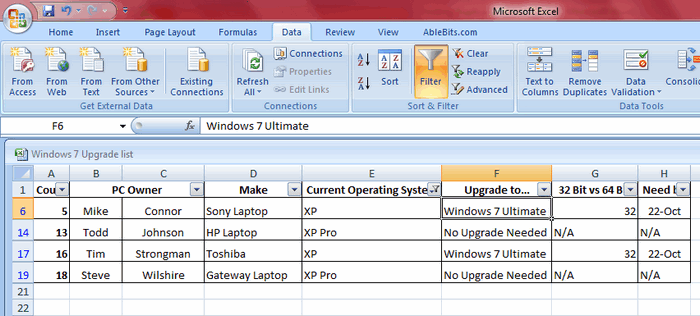
Расширенный фильтр для поиска дубликатов в Excel
На вкладке Data (Данные) справа от команды Filter (Фильтр) есть кнопка для настроек фильтра – Advanced (Дополнительно). Этим инструментом пользоваться чуть сложнее, и его нужно немного настроить, прежде чем использовать. Ваши данные должны быть организованы так, как было описано ранее, т.е. как база данных.
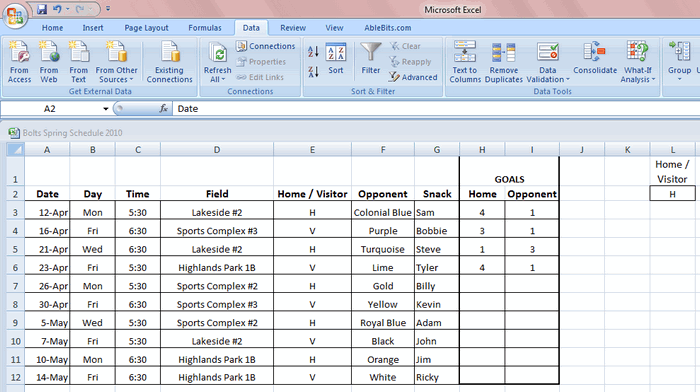
Перед тем как использовать расширенный фильтр, Вы должны настроить для него критерий. Посмотрите на рисунок ниже, на нем виден список с данными, а справа в столбце L указан критерий. Я записал заголовок столбца и критерий под одним заголовком. На рисунке представлена таблица футбольных матчей. Требуется, чтобы она показывала только домашние встречи. Именно поэтому я скопировал заголовок столбца, в котором хочу выполнить фильтрацию, а ниже поместил критерий (H), который необходимо использовать.
Теперь, когда критерий настроен, выделяем любую ячейку наших данных и нажимаем команду Advanced (Дополнительно). Excel выберет весь список с данными и откроет вот такое диалоговое окно:
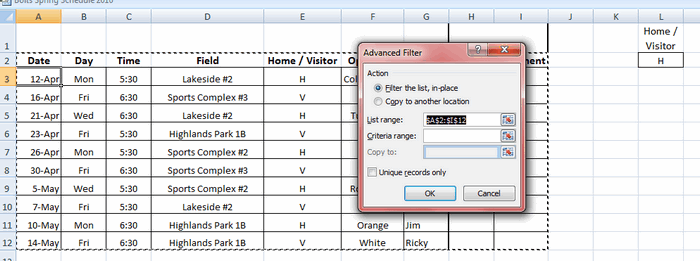
Как видите, Excel выделил всю таблицу и ждёт, когда мы укажем диапазон с критерием. Выберите в диалоговом окне поле Criteria Range (Диапазон условий), затем выделите мышью ячейки L1 и L2 (либо те, в которых находится Ваш критерий) и нажмите ОК. Таблица отобразит только те строки, где в столбце Home / Visitor стоит значение H, а остальные скроет. Таким образом, мы нашли дубликаты данных (по одному столбцу), показав только домашние встречи:
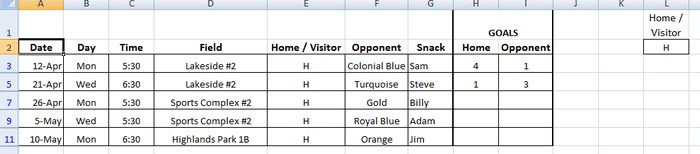
Это достаточно простой путь для нахождения дубликатов, который может помочь сохранить время и получить необходимую информацию достаточно быстро. Нужно помнить, что критерий должен быть размещён в ячейке отдельно от списка данных, чтобы Вы могли найти его и использовать. Вы можете изменить фильтр, изменив критерий (у меня он находится в ячейке L2). Кроме этого, Вы можете отключить фильтр, нажав кнопку Clear (Очистить) на вкладке Data (Данные) в группе Sort & Filter (Сортировка и фильтр).
Как посчитать
Если Вам нужно найти и посчитать количество повторяющихся значений в Excel, создадим для этого сводную таблицу Excel. Добавляем в исходную столбец «Код» и заполняем его «1»: ставим 1, 1 в первых двух ячейка, выделяем их и протягиваем вниз. Когда будут найдены дубликаты для строк, каждый раз значение в столбце «Код» будет увеличиваться на единицу.
Выделяем все вместе с заголовками, переходим на вкладку «Вставка» и нажимаем кнопочку «Сводная таблица».

В следующем окне уже указаны ячейки диапазона, маркером отмечаем «На новый лист» и нажимаем «ОК».

Справой стороны перетаскиваем первые три заголовка в область «Названия строк», а поле «Код» перетаскиваем в область «Значения».

В результате получим сводную таблицу без дубликатов, а в поле «Код» будут стоять числа, соответствующие повторяющимся значениям в исходной таблице – сколько раз в ней повторялась данная строка.
Для удобства, выделим все значения в столбце «Сумма по полю Код», и отсортируем их в порядке убывания.

Думаю теперь, Вы сможете найти, выделить, удалить и даже посчитать количество дубликатов в Excel для всех строк таблицы или только для выделенных столбцов.
Загрузка…
Функция удаления дубликатов
Проще всего избавляться от повторов, доверив удаление автоматической встроенной в программу функции. Этот способ удаления повторяющихся строк в Excel самый быстрый и простой. Хотя не исключена вероятность того, что программа удалит что-то лишнее — или, наоборот, пропустит «неполные» повторения.
Использовать такую методику стоит, если пользователю нужно быстро убрать дублирующиеся данные — или если таких дубликатов слишком много.
Порядок действия для устранения повторов в таблице следующий:
- Выделить область таблицы и открыть вкладку «Данные».
- Перейти к группе команд «Работа с данными».
- Найти иконку функции удаления дубликатов, которая выглядит как два расположенных рядом цветных столбца.
- Кликнуть по ней и, если в столбцах есть заголовки, поставить галочку напротив соответствующего пункта в открывшемся окне.
- Нажать «ОК» и получить в результате файл без дубликатов.
С помощью такой методики можно удалить те строки, которые полностью совпадают друг с другом. Обычно это происходит при копировании информации из 2-3 и более файлов в одну таблицу. Но иногда возникает необходимость удалить дубли в Экселе, где информация совпадает только частично. Это может быть, например, каталог товаров, где есть одни и те же наименования с отличающимися ценами.
Простое удаление не позволит устранить повторы, если стоимость будет другой. Избежать ошибки можно, выбрав при настройке удаления дубликатов только те столбцы, которые будут сравниваться. Например, «Название» и «Марка» — но без «Цены» и «Количества».
Метод 1: удаление дублирующихся строк вручную
Первым делом следует рассмотреть возможность применения самого простого способа работы с дубликатами. Таковым является ручной метод, подразумевающий использование вкладки «Данные»:
Для начала необходимо выделить все ячейки таблицы: зажимаем ЛКМ и выделяем всю область ячеек.
Сверху в панели инструментов нужно выбрать раздел «Данные», чтобы получить доступ ко всем необходимым инструментам.
Внимательно рассматриваем доступные значки и выбираем тот, который имеет два столбца ячеек, раскрашенных в разные цвета. Если навести на этот значок курсор, то высветится наименование «Удалить дубликаты».
Чтобы эффективно использовать все параметры этого раздела, достаточно быть внимательным и не торопиться с установками
К примеру, если таблица имеет «Шапку», то обязательно обратите внимание на пункт «Мои данные содержат заголовки», в нем обязательно должна стоять галочка.
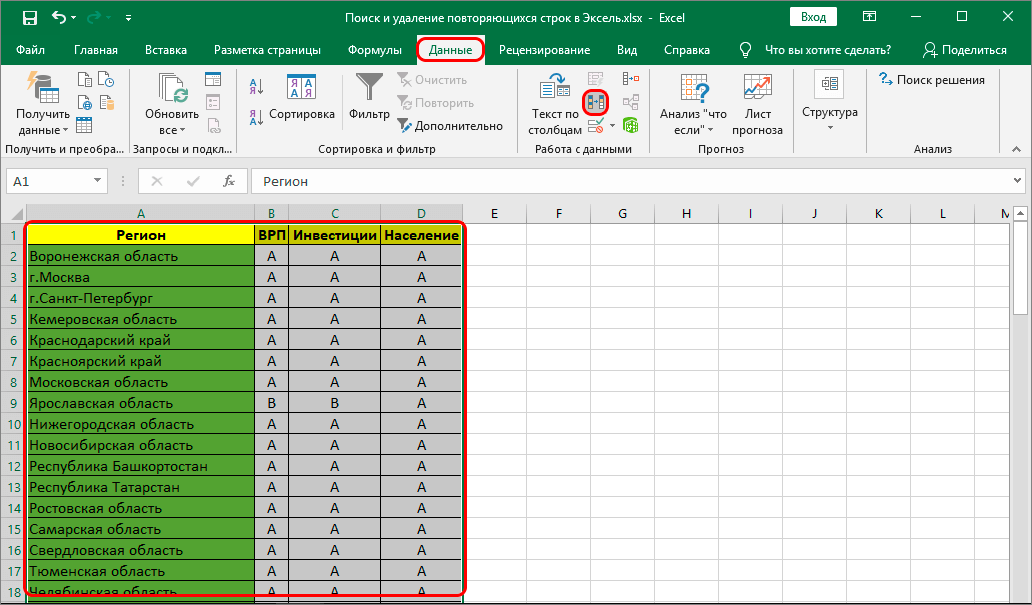 Выделяем таблицу и переходим в раздел инструментария
Выделяем таблицу и переходим в раздел инструментария
- Далее идет окно, в котором отображается информация по столбцам. Нужно выбрать те столбцы, которые вы хотите проверить на наличие дубликатов. Лучше выбирать все, чтобы минимизировать пропуск дублей.
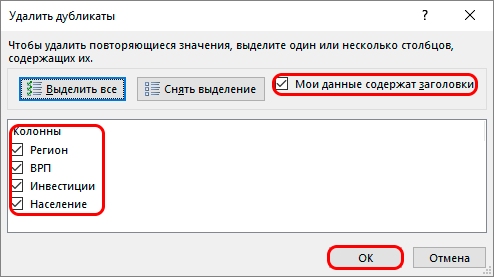 Указываем нужную информацию в окне работы
Указываем нужную информацию в окне работы
- Как только все будет готово, еще раз проверьте отмеченную информацию и нажимайте «ОК».
- Программа Excel начнет автоматически анализировать выбранные ячейки и удалит все совпадающие варианты.
- После полной проверки и удаления дубликатов из таблицы в программе появится окно, в котором будет сообщение о том, что процесс окончен и будет указана информация о том, сколько совпадающих строк было удалено.
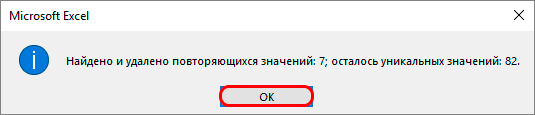 Подтверждаем полученную информацию
Подтверждаем полученную информацию
Вам остается только нажать на «ОК» и можно считать, что все готово. Внимательно выполняйте каждое действие, и результат вас наверняка не разочарует.
Как в Эксель найти повторяющиеся значения?
Для примера я распределил фамилии прославленных футболистов российской эпохи в пару столбцов. Нарочно сделал повторы в столбиках (иллюстрации кликабельны).
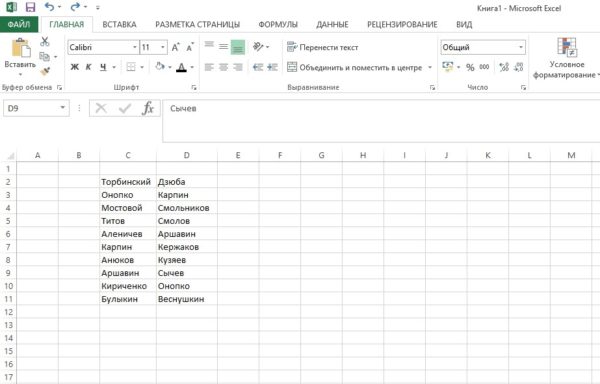
Наша цель – найти повторы в столбцах Excel и выделить их цветом.
Действуем так:
Шаг №1. Выделяем весь диапазон.
Шаг №2. Кликаем на раздел «Условное форматирование» в главной вкладке.
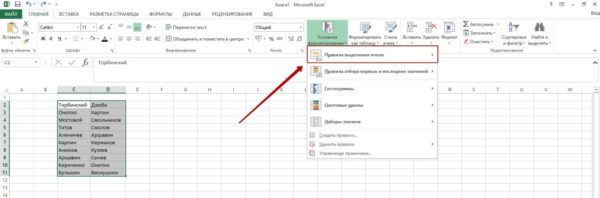
Шаг №3. Наводим на пункт «Правила выделения ячеек» и в появившемся списке выбираем «Повторяющиеся значения».
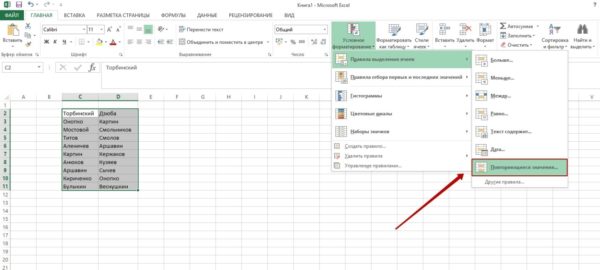
Шаг №4. Возникнет окно. Вам нужно выбрать, хотите ли вы подсветить повторяющиеся или уникальные значения. Также можно установить цвета заливки и текста.
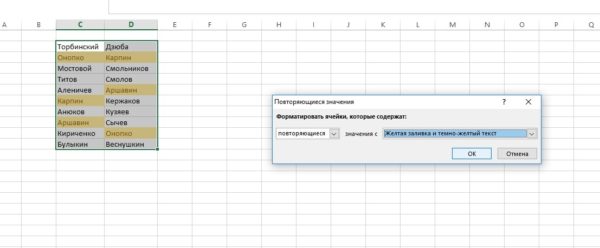
Нажмите «ОК», и вы обнаружите: одинаковые ячейки в двух столбиках теперь выделены! Как видите, это вопрос 30 секунд.
В заключение
Все три метода просты в использовании и помогут Вам с поиском дубликатов:
- Фильтр – идеально подходит, когда в данных присутствуют несколько категорий, которые, возможно, Вам понадобится разделить, просуммировать или удалить. Создание подразделов – самое лучшее применение для расширенного фильтра.
- Удаление дубликатов уменьшит объём данных до минимума. Я пользуюсь этим способом, когда мне нужно сделать список всех уникальных значений одного из столбцов, которые в дальнейшем использую для вертикального поиска с помощью функции ВПР.
- Я пользуюсь командой Find (Найти) только если нужно найти небольшое количество значений, а инструмент Find and Replace (Найти и заменить), когда нахожу ошибки и хочу разом исправить их.
Это далеко не исчерпывающий список методов поиска дубликатов в Excel. Способов много, и это лишь некоторые из них, которыми я пользуюсь регулярно в своей повседневной работе.
