Байт — byte
Битовый порядок байтов
Нумерация битов — это концепция, аналогичная порядку байтов, но на уровне битов, а не байтов. Порядок следования битов или порядок следования битов на уровне битов относится к порядку передачи битов по последовательной среде. Битовый аналог little-endian (младший бит идет первым) используется в RS-232 , HDLC , Ethernet и USB . Некоторые протоколы используют обратный порядок (например, телетекст , I 2 C , SMBus , PMBus и SONET и SDH ). Обычно существует согласованное представление битов независимо от их порядка в байте, так что последний становится актуальным только на очень низком уровне. Одно исключение вызвано функцией некоторых циклических проверок избыточности для обнаружения всех пакетных ошибок до известной длины, которая будет испорчена, если порядок битов отличается от порядка байтов при последовательной передаче.
Помимо сериализации, термины « порядок байтов» и « порядок байтов на уровне битов» используются редко, поскольку редко встречаются компьютерные архитектуры, в которых каждый отдельный бит имеет уникальный адрес. Доступ к отдельным битам или битовым полям осуществляется через их числовые значения или, в языках программирования высокого уровня, через присвоенные имена, последствия которых, однако, могут зависеть от машины или не иметь переносимости программного обеспечения .
Демаркация
Что именно обозначает байт, определяется немного по-разному в зависимости от области применения. Этот термин может означать:
- единица измерения для объема данных из 8 бит с блоком символом «B», в результате чего порядок отдельных бит не важен. Символ единицы не следует путать с символом единицы «B», принадлежащим единице Bel .
- упорядоченная компиляция ( ) из 8 бит, формальное обозначение которой в соответствии с ISO — октет (1 байт = 8 бит). Иногда октет делится на две половины ( полубайта ) по 4 бита каждая, при этом каждый полубайт может быть представлен шестнадцатеричным числом . Таким образом, октет может быть представлен двумя шестнадцатеричными цифрами.
- наименьший объем данных определенной технической системы , обычно адресуемый через адресную шину . Количество бит на символ почти всегда является натуральным числом. Примеры:
- для телекса : 1 символ = 5 бит
- Для компьютеров семейства PDP : 1 символ = бит = приблизительно 5,644 бит (код Radix 50). По сравнению с 6 битами это приводит к экономии нескольких бит на символьную строку , которые могут использоваться, например, для целей управления. Однако границы байтов проходят сквозь биты, что может затруднить анализ содержимого.бревно2(50){\ displaystyle \ log _ {2} (50)}
- для IBM 1401 : 1 символ = 6 бит
- с ASCII : 1 символ = 7 бит
- для IBM-PC : 1 символ = 8 бит = 1 октет
- с Nixdorf 820 : 1 символ = 12 бит
- Для компьютерных систем типов UNIVAC 1100/2200 и OS2200 Series: 1 символ = 9 бит (код ASCII) или 6 бит (код FIELDATA)
- Для компьютеров семейства PDP-10 : 1 символ = 1… 36 бит, длина байта выбирается произвольно.
- типа данных в языках программирования . Количество бит на байт может варьироваться в зависимости от языка программирования и платформы (в основном 8 бит).
- ISO- определяет 1 байт как непрерывную последовательность не менее 8 бит.
Сегодня в большинстве компьютеров эти определения (наименьшая адресуемая единица, тип данных в языках программирования, тип данных C) объединяются в одно и имеют одинаковый размер.
Из-за широко распространенного использования систем, основанных на восьми битах (или степени двойки), термин «байт» используется для обозначения 8-битного размера, который на формальном языке (согласно стандартам ISO) правильно является октетом (от английского octet ) называется. В немецком языке термин «байт» (в смысле 8 бит) используется как единица измерения для спецификаций размера. Во время передачи байт может передаваться параллельно (все биты одновременно) или последовательно (все биты один за другим). Проверочные биты часто добавляются для проверки правильности . Для передачи больших объемов возможны дополнительные протоколы связи . На 32-битных компьютерах 32 бита (четыре байта) часто передаются вместе за один шаг, даже если необходимо передать только 8-битный кортеж. Это позволяет упростить алгоритмы, необходимые для расчета, и уменьшить набор команд для компьютера.
Как и в случае с другими юнитами, рядом с полным названием юнитов, соответственно, есть символ юнита . Для бита и байта это:
| Сокращенное название | полное имя |
|---|---|
| бит (редко «б») | немного |
| B (редко «байт») | байт |
Полное имя в основном подвержено нормальному склонению . Из-за большого сходства сокращений с письменными названиями единиц, а также с соответствующими формами множественного числа в английском языке, сокращения единиц «бит» и «байт» иногда снабжены множественным числом s.
Таблица байтов:
1 байт = 8 бит
1 Кб (1 Килобайт) = 210 байт = 2*2*2*2*2*2*2*2*2*2 байт = = 1024 байт (примерно 1 тысяча байт – 103 байт)
1 Мб (1 Мегабайт) = 220 байт = 1024 килобайт (примерно 1 миллион байт – 106 байт)
1 Гб (1 Гигабайт) = 230 байт = 1024 мегабайт (примерно 1 миллиард байт – 109 байт)
1 Тб (1 Терабайт) = 240 байт = 1024 гигабайт (примерно 1012 байт). Терабайт иногда называют тонна.
1 Пб (1 Петабайт) = 250 байт = 1024 терабайт (примерно 1015 байт).
1 Эксабайт = 260 байт = 1024 петабайт (примерно 1018 байт).
1 Зеттабайт = 270 байт = 1024 эксабайт (примерно 1021 байт).
1 Йоттабайт = 280 байт = 1024 зеттабайт (примерно 1024 байт).
В приведенной выше таблице степени двойки (210, 220, 230 и т.д.) являются точными значениями килобайт, мегабайт, гигабайт. А вот степени числа 10 (точнее, 103, 106, 109 и т.п.) будут уже приблизительными значениями, округленными в сторону уменьшения. Таким образом, 210 = 1024 байта представляет точное значение килобайта, а 103 = 1000 байт является приблизительным значением килобайта.
Такое приближение (или округление) вполне допустимо и является общепринятым.
Ниже приводится таблица байтов с английскими сокращениями (в левой колонке):
1 Kb ~ 103 b = 10*10*10 b= 1000 b – килобайт
1 Mb ~ 106 b = 10*10*10*10*10*10 b = 1 000 000 b – мегабайт
1 Gb ~ 109 b – гигабайт
1 Tb ~ 1012 b – терабайт
1 Pb ~ 1015 b – петабайт
1 Eb ~ 1018 b – эксабайт
1 Zb ~ 1021 b – зеттабайт
1 Yb ~ 1024 b – йоттабайт
Выше в правой колонке приведены так называемые «десятичные приставки», которые используются не только с байтами, но и в других областях человеческой деятельности. Например, приставка «кило» в слове «килобайт» означает тысячу байт. В случае с километром она соответствует тысяче метров, а в примере с килограммом она равна тысяче грамм.
Продолжение следует…
Возникает вопрос: есть ли продолжение у таблицы байтов? В математике есть понятие бесконечности, которое обозначается как перевернутая восьмерка: ∞.
Понятно, что в таблице байтов можно и дальше добавлять нули, а точнее, степени к числу 10 таким образом: 1027, 1030, 1033 и так до бесконечности. Но зачем это надо? В принципе, пока хватает терабайт и петабайт. В будущем, возможно, уже мало будет и йоттабайта.
Напоследок парочка примеров по устройствам, на которые можно записать терабайты и гигабайты информации.
Есть удобный «терабайтник» – внешний жесткий диск, который подключается через порт USB к компьютеру. На него можно записать терабайт информации. Особенно удобно для ноутбуков (где смена жесткого диска бывает проблематична) и для резервного копирования информации. Лучше заранее делать резервные копии информации, а не после того, как все пропало.
Флешки бывают 1 Гб, 2 Гб, 4 Гб, 8 Гб, 16 Гб, 32 Гб , 64 Гб и даже 1 терабайт.
DVD-диски рассчитаны на большее количество информации: 4.7 Гб, 8.5 Гб, 9.4 Гб и 17 Гб.
Упражнения по компьютерной грамотности
описаны в статье “Байт, килобайт, мегабайт…”
Статья закончилась, но можно еще прочитать:
Распечатать статью
Получайте актуальные статьи по компьютерной грамотности прямо на ваш почтовый ящик. Уже более 3.000 подписчиков
.
Важно: необходимо подтвердить свою подписку! В своей почте откройте письмо для активации и кликните по указанной там ссылке. Если письма нет, проверьте папку Спам
Приложения
В архитектуре x86 32-битное приложение обычно означает программное обеспечение, которое обычно (не обязательно) использует 32-битное линейное адресное пространство (или модель плоской памяти ), возможное с чипами и более поздних версий. В этом контексте термин появился потому , что DOS , Microsoft Windows и OS / 2 были изначально написаны для 8088/8086 или , 16-разрядных микропроцессоров с сегментированным адресным пространством, где программы должны были переключаться между сегментами, чтобы достичь более 64 килобайт. из кода или данных. Поскольку это занимает довольно много времени по сравнению с другими операциями на машине, производительность может снизиться
Более того, программирование с использованием сегментов имеет тенденцию усложняться; специальные ключевые слова дальнего и ближнего действия или модели памяти должны были использоваться (с осторожностью) не только на языке ассемблера, но и на языках высокого уровня, таких как Паскаль , скомпилированный БЕЙСИК , Фортран , C и т. д.
80386 и его последователи полностью поддерживают 16-битные сегменты 80286, но также и сегменты для 32-битных адресных смещений (с использованием новой 32-битной ширины основных регистров). Если базовый адрес всех 32-битных сегментов установлен на 0 и сегментные регистры не используются явно, о сегментации можно забыть, и процессор будет иметь простое линейное 32-битное адресное пространство. Операционные системы, такие как Windows или OS / 2, предоставляют возможность запускать 16-битные (сегментированные) программы, а также 32-битные программы. Первая возможность существует для обратной совместимости, а вторая обычно предназначена для использования при разработке нового программного обеспечения .
Отдельные ссылки и комментарии
- Эта связь между порядком байтов и битов уже была установлена (стр. 3).
- с помощью машинных инструкций или функций C и начинается на каждой машине на начало строки символов и тем самым оценивает более низкие цифры адреса как имеющие более высокий приоритет, т.е. действует в стиле Big Endian. Этот перенос порядка из отдельных байтов в многозначные поля, если он начинается с первой цифры, называется лексикографическим порядком . ( . Проверено 26 марта 2015 г.) Упоминания символьных строк («строк») в литературе, например B. и , в контексте его байты часто ограничиваются режимом передачи.
- Чтобы инструкция, которая потенциально включает в себя большое количество машинных циклов, не монополизировала главный процессор , она была спроектирована так, чтобы ее можно было прерывать, и после аппаратного прерывания ее можно было продолжить с того места, где она была прервана. (См. Принципы работы ESA / 390, глава 7-44 Общие инструкции 25 июня 2014 г.)
- . en.cppreference.com. Проверено 6 марта 2014 года.
- Герд Кювелер, Дитрих Швох: ( немецкий ), 5-е издание, том 2, Vieweg, перепечатка: Springer-Verlag, 4 октября 2007 г., ISBN 3834891916 , ( по состоянию на 5 августа 2015 г.).
Порядок байтов в памяти
Удобным средством демонстрации порядка байтов действии и объяснения разницы между прямым и обратным порядками является процесс хранения цифровых данных. Представьте, что мы используем 8-разрядный микроконтроллер. Всё аппаратное обеспечение в этом устройстве, включая ячейки памяти, предназначено для 8-битных данных. Таким образом, адрес 0x00 может хранить один байт, адрес 0x01 тоже хранит один байт, и так далее.
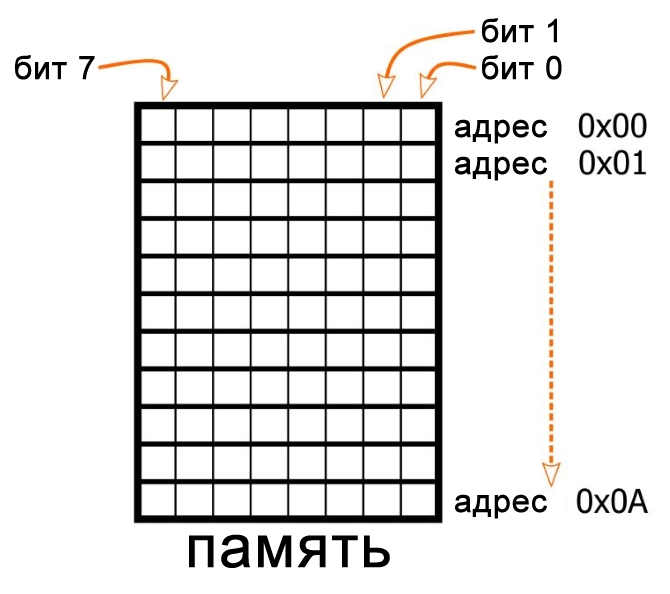 Эта схема показывает 11 байтов памяти, то есть 11 ячеек памяти, причем каждая ячейка хранит 8 бит данных
Эта схема показывает 11 байтов памяти, то есть 11 ячеек памяти, причем каждая ячейка хранит 8 бит данных
Допустим, мы решили запрограммировать этот микроконтроллер, используя компилятор C, который позволяет нам определять 32-разрядные (т.е. 4-байтовые) переменные
Компилятор должен хранить эти переменные в смежных ячейках памяти, но что не очень понятно, так это то, в самом младшем адресе памяти должен храниться наибольший значащий байт (most significant byte, MSB – обратите внимание на заглавную «B») или наименьший значащий байт (least significant byte, LSB)
Другими словами, должна ли система использовать порядок памяти от старшего к младшему (прямой порядок, big-endian) или от младшего к старшему (обратный порядок, little-endian)?
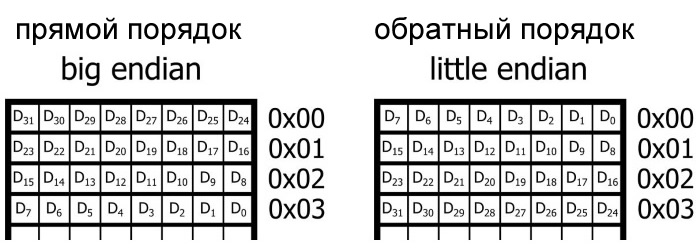 Хранение данных с прямым порядком и с обратным порядком. «D» относится к 32-разрядному слову данных, а номера индексов указывают на отдельные биты от MSb (D31) до LSb (D)
Хранение данных с прямым порядком и с обратным порядком. «D» относится к 32-разрядному слову данных, а номера индексов указывают на отдельные биты от MSb (D31) до LSb (D)
Здесь на самом деле нет правильного или неправильного ответа – любая договоренность может быть совершенно эффективной. Решение между прямым и обратным порядком может быть основано, например, на поддержании совместимости с предыдущими версиями данного процессора, что, конечно, поднимает вопрос о том, как инженеры приняли решение для первого процессора в этом семействе. Я не знаю; возможно, генеральный директор подбросил монету.
Изображений
В цифровых изображениях / изображениях 32-битное значение обычно относится к цветовому пространству RGBA ; то есть 24-битные полноцветные изображения с дополнительным 8-битным альфа-каналом . Другие форматы изображений также определяют 32 бита на пиксель, например RGBE .
В цифровых изображениях 32-битный формат иногда относится к форматам изображений с расширенным динамическим диапазоном (HDR), которые используют 32 бита на канал, всего 96 бит на пиксель. 32-битные изображения на канал используются для представления значений ярче, чем позволяет цветовое пространство sRGB (ярче белого); затем эти значения можно использовать для более точного сохранения ярких светов при уменьшении экспозиции изображения, при просмотре через темный фильтр или тусклое отражение.
Например, отражение в нефтяном пятне — это лишь часть отражения от зеркальной поверхности. Изображения HDR позволяют отражать светлые участки, которые все еще можно увидеть как ярко-белые области, а не тускло- серые формы.
Байт
С развитием компьютеров, появилась потребность в большем количестве значений для байта. В 1963-м году появилась первая редакция семибитной кодировки ASCII. Поэтому байты стали занимать 7 бит. 7 бит, требующиеся для одного символа данной кодировки позволяют использовать 128 значений. В этой кодировке уже были включены строчные латинские символы, и больший набор управляющих и арифметических символов.
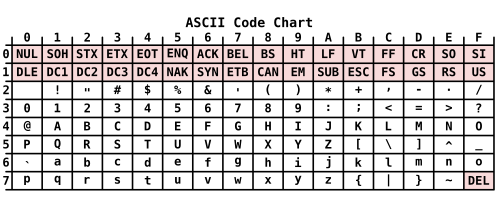
Всемирное распространение компьютеров подтолкнуло дальнейшее расширение границ занимаемых байтом. Для различных языков требовалось чтобы таблица символов также могла хранить алфавит того языка, где используется данная ЭВМ. На текущий момент восемь — это последнее и видимо окончательное количество бит составляющих байт. Соответственно байт может принимать 256 значений. По сравнению с таблицей ASCII в. новых таблицах символов — организовалось 128 вакантных мест. Теперь я думаю можно рассказать как значения хранятся в различных кириллических кодировках.
Кодировки
Итак, чтобы хранить символы не входящие в ASCII, необходимо было придумать новые кодировки. Поскольку до этого таблица ASCII была наиболее подходящей (были и другие), то она и пошла в основу новых кодировок. Поэтому следующие кодировки отличаются только значениями начиная с 80 (hex). Для наглядности оставлю только кириллические символы.

Так выглядела наиболее популярная кодировка под DOS. Примечательно что файлы в этой кодировке до сих пор встречаются. Как правило среди устаревшей архивной информации, в программах WinRar, Блокнот и WordPad, до сих пор есть опции «открыть как текст DOS», впрочем последними двумя мало кто пользуется =).
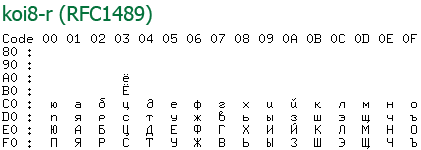
Кодировка koi8 была примечательна тем, что русские буквы там располагались на позициях английских звуков из нижней половины (т. е. ASCII). Это когда-то давно позволяло смягчить переход со старых серверов понимающие только ascii на новые, что было актуально среди почтовых серверов. Смысл был в том что если отправленное вами письмо приходило на старый сервер, то пользователю оно показывалось как транслит, что позволяло хоть как-то понять текст письма.

Самая популярная у нас в России однобайтная кодировка, на сегодняшний день, это именно «windows-1251». Разумеется популярность её целиком обусловлена популярностью Windows среди других операционных систем. Возможностей кодировки вполне хватает для использования её в широком круге задач. Например движок моего блога, по-умолчанию, использует для работы именно данную кодировку.

Я не могу не упомянуть о кодировке ISO, Удивительно, но несмотря на то что её никто никогда не использовал, эта кодировка является единственной кодировкой имеющей статус стандарта.
На примере данных кодировок видно, как один байт может хранить какое угодно символьное значение русского и английского языков, а также цифр и знаков пунктуации.
Но что делать когда этого не достаточно?
Многобайтные кодировки
Если вам хочется создать кодировку которая бы имела коды одновременно для русского и греческого алфавита? Одним байтом тут не отделаться. Появилась задача разработать кодировку один знак которой может занимать больше чем один байт, так как два байта могут принимать уже 2^16 = 65536 значений, а четыре байта аж 4294967296. Поэтому сначала придумали стандарт кодирования символов — Юникод, который включал бы в себя максимально полный перечень символов которые может принимать один знак.
Первая версия Юникода (Unicode 1991 г.) представляла собой 16-битную кодировку с фиксированной шириной символа; общее число разных символов было 216 (65 536).
Вторая версия Юникода (UCS-2), стала называться UTF-16, она позволяла гораздо расширить количество возможных значений, также используя для символов 16-битные последовательности (т. е. по 2 или по 4 байта на символ).
Кодировка UTF-32 (UCS-4) использует по 32 бита, или 4 байта на хранение одного символа. Строго говоря, стандарт Unicode не описывает символы со значениями выше 2^21, так что хватило бы и трёх байт, на символ, вероятно компьютеры работают несколько быстрее с мелкими блоками памяти кратными двум, или для того чтобы в сектор диска попадало кратное количество символов. Так или иначе это единственная из многобайтных кодировок с постоянной длиной. Помимо недостатка — использования четырёх байт на символ, у неё есть и очевидное преимущество — возможность прямой адресации к N-ному символу. В других кодировках требуется последовательное вычисление позиции каждого символа. Поэтому текстовые редакторы, внутри себя хранят всю информацию в виде UCS-4.
В 1992 году Кеном Томпсоном и Робом Пайком был изобретён формат UTF-8. Он отличается тем, что он ASCII совместим, и значения из таблицы Юникода могут занимать от 1 до 4х символов.
Символы UTF-8 получаются из Unicode следующим образом:
| Unicode | UTF-8 | Представленные символы |
|---|---|---|
| — | ASCII, в том числе английский алфавит, простейшие знаки препинания и арабские цифры | |
| — | кириллица, расширенная латиница, арабский, армянский, греческий, еврейский и коптский алфавит; сирийское письмо, тана, нко; МФА; некоторые знаки препинания | |
| — | все другие современные формы письменности, в том числе грузинский алфавит, индийское, китайское, корейское и японское письмо; сложные знаки препинания; математические и другие специальные символы | |
| — | музыкальные символы, редкие китайские иероглифы, вымершие формы письменности |
Символы, в кодировке UTF-8, могут занимать до шести байт, но Unicode не определяет символов выше , поэтому символы Unicode могут иметь максимальный размер в 4 байта в UTF-8.
Приставки К, М, Г, Т («кило-», «киби-» и т.д.)
…чтобы измерять большие объемы данных, используют кратные приставки (это как «килограмм»). Привычная же нам приставка «кило-» означает умножение на 1000 (103), но в двоичной системе счисления используют два в десятой степени (210).
Давайте же вместе с сайтом IT-уроки разберемся в этом запутанном вопросе.
История введения двоичных приставок
Для обозначения величины 210=1024 байт, ввели двоичную приставку «К» (именно прописная буква «К»), но в разговорной речи единицу «К» стали называть «кило», что не совсем одно и то же. Чтобы избежать путаницы, ввели названия приставкам:
Т.е. второй слог изменили с привычного на «би», «бинарный».
Но путаница не исчезла, многие расшифровывали «К» и «М» привычными «кило» и «мега». Даже международные стандарты по-разному интерпретировали расшифровку двоичных приставок. Кроме того, производители добавили масла в огонь внесли свой вклад в запутывание ситуации (одни считали 210, другие 103).
В итоге, чтобы окончательно убрать несоответствие, изменили не только названия, но и приставки:
Как Вы думаете, помогло? Конечно же, нет
В обиходе говорят «кило», в программах ОС Windows пишут «К», в Linux обозначают «Ки», производители жестких и оптических дисков пишут «К», а имеют в виду «Ки» и т.д.
Что же делать обычному пользователю?
Если подвести итог всему сказанному, то на сегодняшний день три варианта использования двоичных приставок, их мы и сведем в три таблицы.
1. Обычное использование двоичных приставок
В свойствах файлов почти все программы, да и сама операционная система Windows использует приставку в виде прописной буквы «К», «М», «Г» и т.д. Производители оперативной памяти используют тот же принцип. То есть можно пользоваться следующей таблицей:

Двоичные приставки в ОС Windows и у производителей ОЗУ 1 Кбайт (КБ или KB или Kbyte) = 1024 байт
Эта «К» на самом деле двоичная приставка «киби» (а не «кило», как все говорят).
2. Правильное использование двоичных приставок
В других операционных системах, а также в профессиональных обзорах серьезных ИТ-изданий сразу пишут «Киб», «МиБ», «ГиБ», чтобы не было сомнений, о чем идет речь.

Двоичные приставки в ОС Linux, OS X и в профессиональных обзорах 1 кибибайт (КиБ или KiB или kebibyte) = 1024 байт
3. Использование десятичных приставок
Если используется приставка «кило», «мега», «гига» и т.д., то имеются в виду следующие соотношения:

Десятичные приставки используют производители накопителей (Жесткие диски, флэшки, DVD-диски) 1 килобайт (кБ или kB или kbyte) = 1000 байт
Куда исчезли 70 гигабайт на жестком диске???
Посмотрим, как Windows видит два моих жестких диска 500 ГБ и 1 ТБ:

Жесткий диск 500 ГБ отображается как 465.76 ГБ, а винчестер объемом 1000 ГБ содержит всего 931.51 гигабайт.
Наверное, Вы уже догадались, почему жесткий диск объемом 1 Терабайт в ОС Windows отображается как 931 ГБ, а не 1000.
Так что, не ругайте производителей и уж тем более компьютерную фирму, всё отмерено верно, но разными рулетками
Т.е. 70 гигабайт никуда не делись, просто гибибайт на жестком диске меньше, чем гигабайт.
Не запутались? Тогда еще один пример.
«Почему на флешке меньше места?»
То же самое и с флэш-накопителями. Если Вы посмотрите на свойства своей флэшки, то (к примеру) вместо 16 GB, указанных на корпусе, увидите 14.9 ГБ!!!
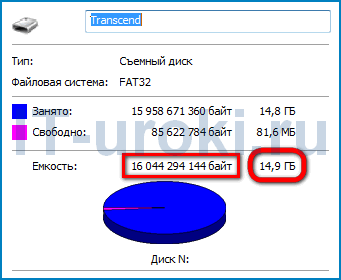
На флешке вместо 16 GB — 14.9 ГБ
Теперь Вы знаете, что 1.1 ГБ «потерялся» при пересчете из килобайт в кибибайты.
Пример: интерпретация шестнадцатеричного дампа
Цель дампа — четкое представление содержимого памяти , например, для анализа ошибок. Для машин, чья ячейка памяти (байт) состоит из 8 бит, выбирается представление в шестнадцатеричной системе , в которой 2 8 = 256 = 16 2 различных содержимого байта выражаются двумя шестнадцатеричными цифрами. Это кодирование , которое непосредственно охватывает как двоичные значения, так и машинные инструкции, а также десятичные значения в коде BCD , обычно сопровождается столбцом, который представляет каждый отдельный байт как буквенный символ, если это возможно, так что любые тексты в памяти можно легче распознать и прочитать.
В следующем примере показано, как два последовательных байта (4 полубайта)
должны интерпретироваться в шестнадцатеричном дампе с читаемым шестнадцатеричным содержимым .
| Hexdump | 2 беззнаковых 8-битных двоичных числа | 1 беззнаковое 16-битное двоичное число | |||||||||
| Байты | текст | Byte0: биты | шестнадцатеричный | декабрь | Байт1: биты | шестнадцатеричный | декабрь | Биты | шестнадцатеричный | декабрь | |
| удобочитаемый | |||||||||||
| прямой порядок байтов | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| интерпретация | |||||||||||
| прямой порядок байтов | |||||||||||
| интерпретация |
Если поле состоит только из одного байта (8-битное двоичное число со знаком или без него ) или его совокупности (например, текст в коде ISO 8859 ) — в таблице столбцы «2 беззнаковых 8-битных двоичных числа» — тогда Дифференциация интерпретации двух форматов big- или little-endian не различается.Внутренняя последовательность битов на байт зеркально отражается между двумя форматами точно так же, как и последовательность байтов на целое число (см. ). Из-за условий шестнадцатеричного представления шестнадцатеричный дамп полностью фиксируется побайтно, так что нет разницы между прямым и обратным порядком байтов.
Если поле состоит из более чем одного байта, вступает в игру так называемое «соглашение Intel» с прямым порядком байтов. Это означает, что — в отличие от прямого порядка байтов — младший байт сохраняется в младшем адресе памяти, а старшие байты — в последующих адресах памяти. В результате, например, в случае целочисленных полей длиной 16, 32 или 64 бита, два шестнадцатеричных представления дампа являются побайтным зеркальным копированием друг друга. Чтобы было понятнее, столбец «1 беззнаковое 16-битное двоичное число» в таблице показывает содержимое первого из 2 байтов с надстрочной линией.
Заключение
Очень жаль, что универсальная система порядка байтов не была создана еще в начале цифровой эпохи. Я даже не хочу знать, сколько коллективных часов человеческой жизни было посвящено решению проблем, вызванных несовпадающим порядком байтов.
В любом случае, мы не можем изменить прошлое, и мы также вряд ли убедим каждую компанию, производящую полупроводниковую технику и программное обеспечение, пересмотреть свои производственные линии для достижения единого универсального порядка байтов. Что мы можем сделать, так это добиваться согласованности наших собственных проектов и предоставлять четкую документацию, если существует вероятность конфликта между двумя составляющими частями системы.
